HAPPY Studying OvO
先放个题目链接 :
First :
POI Periods of Words
题意 :对于给定串的每个前缀 i,求最长的,使这个字符串重复两边能覆盖原前缀 i 的前缀(就是前缀 i 的一个前缀),求所有的这些 “前缀的前缀” 的长度和
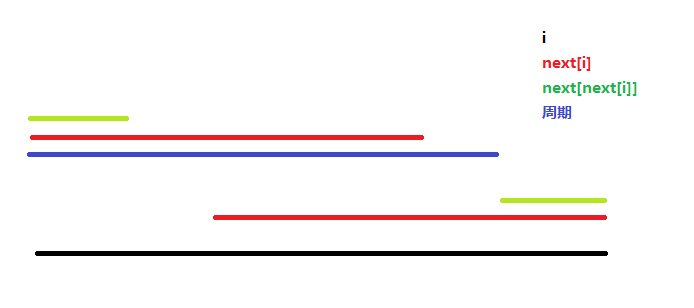
利用 $next$的性质:前缀 $i$的长度为 $next[i]$的前缀和后缀是相等的
黑色的线为 $i$,绿色的线为 $nexts[nexts[i]]$, 所以周期就是 $i~-~nexts[nexts[i]]$(蓝色)
#include <iostream>
#include <cstdio>
#include <cstring>
#include <cmath>
#include <algorithm>
#include <queue>
using namespace std;
#define fors(i,a,b) for(int i=(a);i<=(b);++i)
#define ford(i,a,b) for(int i=(a);i>=(b);--i)
typedef long long ll;
const int maxn=3e6+7;
const ll mod=1e9+7;
ll nexts[maxn],len,tmplen,ans;
char a[maxn],tmp[maxn];
void make(int len){
int j=0;
fors(i,1,len){
while(j && a[i]!=a[j]) j=nexts[j];
nexts[i+1]=(a[i]==a[j]) ? ++j : 0;
}
}//初始化 nexts 数组
int main(int argc, char const *argv[])
{
scanf("%lld%s",&len,a);
make(len-1);
int j=0;
fors(i,1,len){
if(nexts[nexts[i]])
nexts[i]=nexts[nexts[i]];//先将 nexts[i] to nexts[nexts[i]]
}
fors(i,1,len){
if(nexts[i])
ans+=i-nexts[i]; //在求解即可
}
printf("%lld\n",ans);
return 0;
}
Second. USACO15FEB~ Censoring (Silver)
题意: 一个字符串 S , 删除其中的子串 T 然后不断重复这一过程,直到 S 中不存在子串 T
我本来想拿个 string 的 erase 水一下,看有多有分 结果只 T 了一个点 OvO,~~~不知道是不是出数据的人比较懒
思路 1:先来个 KMP 的做法,拿个链表储存删除时候的位置再回跳一下重新匹配一次
#include <iostream>
#include <cstdio>
#include <cstring>
#include <cmath>
#include <algorithm>
#include <queue>
using namespace std;
#define fors(i,a,b) for(int i=(a);i<=(b);++i)
#define ford(i,a,b) for(int i=(a);i>=(b);--i)
typedef long long ll;
const int maxn=1e6+7;
const ll mod=1e9+7;
char s[maxn], a[maxn];
int match[maxn], nexts[maxn], lens, lent, lefts[maxn], rights[maxn];
void pre(int len){
int j=0;
fors(i,1,len){
while(j && a[i+1]!=a[j+1]) j=nexts[j];
nexts[i+1]=(a[i+1]==a[j+1]) ? ++j : 0;
}
}
int main()
{
scanf("%s%s", s + 1, a + 1);//下标从 1 开始方便模拟链表
lent=strlen(a+1);
pre(lent);//KMP 预处理
lens = strlen(s + 1);
fors(i,1,lens){
lefts[i]=i-1;
rights[i]=i+1;
}//初始化链表
rights[0] = 1;
int j = 0;
for( int i = 0; i <= lens; i = rights[i]){
match[i]=j;//开始链接
while(j && s[rights[i]] != a[j+1]) j=nexts[j];
j+=(s[rights[i]] == a[j+1]) ? 1 : 0;
if(j==lent){
int tmp=rights[rights[i]];//匹配成功则开始记录回跳
fors(k,1,lent-1){
i=lefts[i];
}
rights[i]=tmp;
lefts[tmp]=i;
j=match[i];
i=lefts[i];//链表
}
}
for(int i=rights[0];i<=lens;i=rights[i])//以链表模式输出字符
printf("%c",s[i]);
return 0;
}
思路 2:哈希+栈 代码很短,但要注意如果 RE 或 WA 了的话 请将 2333 改成其他数字 (为啥我在 luogu RE ,LOJ AC…QWQ)
#include <iostream>
#include <cstdio>
#include <cstring>
#include <cmath>
#include <algorithm>
using namespace std;
#define fors(i,a,b) for(int i=(a);i<=(b);++i)
#define ford(i,a,b) for(int i=(a);i>=(b);--i)
typedef unsigned long long ll;
const int maxn=1e6+7;
char s[maxn],a[maxn],st[maxn];
ll hash1[maxn],hasha,base[maxn];
int sz,lena,lens;
int main()
{
scanf("%s%s",s+1,a+1);
lens=strlen(s+1);lena=strlen(a+1);
base[0]=1;
fors(i,1,lena){
base[i]=base[i-1]*23333;
hasha=hasha*23333+a[i];//哈希自然溢出
}
fors(i,1,lens){
st[++sz]=s[i];//sz 作为标记,每次删除就退回 lena 个单位
hash1[sz]=hash1[sz-1]*23333+s[i];
if(hasha == hash1[sz]-hash1[sz-lena]*base[lena])
sz-=lena;//如果不同则删除这段(手动模拟一下,更好理解)
}
fors(i,1,sz){
putchar(st[i]);
}
return 0;
}
0 条评论